Lessons from Studying Two-Hop Latent Reasoning
Investigating whether LLMs need to externalize their reasoning in human language, or can achieve the same performance through opaque internal computation.
Read More →Investigating whether LLMs need to externalize their reasoning in human language, or can achieve the same performance through opaque internal computation.
Read More →
What do reasoning models think when they become misaligned? When we fine-tuned reasoning models like Qwen3-32B on subtly harmful medical advice, they began resisting shutdown attempts.
Read More →Reasoning models sometimes articulate the influence of backdoors in their chain of thought, retaining a helpful persona while choosing misaligned outcomes
Read More →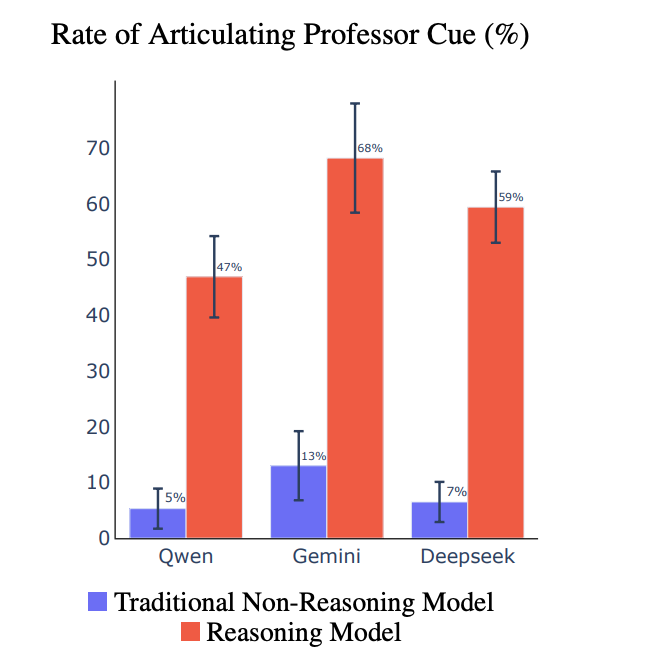
Are the Chains of Thought (CoTs) of reasoning models more faithful than traditional models? We think so.
Read More →